Як навчається нейронна мережа: покроковий розбір від нуля
- ШІ , Освіта
- 05 Apr, 2025
Натхненно серією 3Blue1Brown про нейронні мережі. Ця стаття — компаньйон до інтерактивного інспектора нейронної мережі, де ви можете самостійно прокрутити кожну епоху навчання і подивитися на кожне число всередині.
Що ми будемо будувати
Уявіть, що ви хочете навчити комп’ютер розрізняти рукописні цифри 0, 1 і 2. Не через купу if-ів і правил (“якщо пікселі зверху зліва — це нуль”), а через навчання на прикладах — так, як вчиться дитина.
Ми побудуємо найпростішу нейронну мережу:
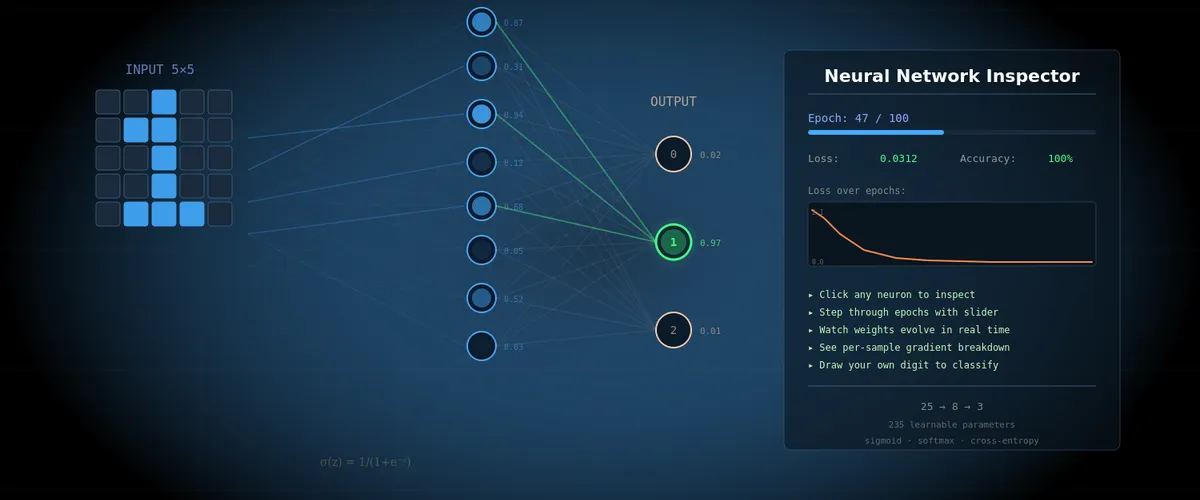
- 25 вхідних нейронів — кожен відповідає одному пікселю зображення 5×5
- 8 прихованих нейронів — “детектори ознак”, які навчаться знаходити патерни
- 3 вихідних нейрони — по одному на кожну цифру (0, 1, 2)
Всього 235 параметрів (ваги та зміщення), які мережа повинна підібрати самостійно. Це крихітна мережа — для порівняння, мережа з відео 3Blue1Brown має 13 002 параметри, а GPT-4 — сотні мільярдів. Але принципи роботи абсолютно ті самі.
🧪 Інтерактивний інспектор: Відкрийте інструмент і встановіть епоху на 0. Ви побачите початковий стан мережі — випадкові ваги, рівномірний розподіл виходу (~33% на кожну цифру). Мережа ще нічого не знає.
Частина 1: Що таке нейрон
Забудьте про біологію. У нашому контексті нейрон — це коробочка, в якій лежить число. Це число називається активація (activation, позначається a), і воно завжди між 0 і 1.
a = 0— нейрон “вимкнений”, сигналу немаєa = 1— нейрон “увімкнений на повну”, максимальний сигналa = 0.73— нейрон “частково активний”
Як каже Grant Sanderson (3Blue1Brown): “Коли я кажу ‘нейрон’, все що я хочу, щоб ви думали — це ‘щось, що тримає число’.”
В інспекторі нейрони відображаються як кружечки на графі. Чим яскравіший кружечок — тим вища активація.
Вхідні нейрони
Наші 25 вхідних нейронів — це просто пікселі зображення 5×5. Кожен піксель має значення 0 (чорний) або 1 (білий). Коли ми подаємо зображення цифри “0”, деякі пікселі = 1 (де намальована цифра), інші = 0 (фон).
🧪 В інспекторі: Наведіть курсор на будь-який вхідний нейрон. Тултіп покаже:
x[12] = 1(піксель увімкнений) абоx[3] = 0(піксель вимкнений), та таблицю ваг, що йдуть від цього пікселя до кожного з 8 прихованих нейронів.
Частина 2: Як нейрони з’єднані — ваги і зміщення
Ваги (weights, w)
Кожен нейрон одного шару з’єднаний з кожним нейроном наступного шару. Кожне таке з’єднання має вагу — число, яке визначає силу і напрямок зв’язку.
Аналогія: уявіть групу друзів, які вирішують, куди піти обідати. Кожен має свою перевагу — хтось дуже хоче піцу (вага +0.8), хтось категорично проти суші (вага -0.5), комусь байдуже (вага ~0). Фінальне рішення — це сума всіх “голосів”, зважених на силу переваги кожного.
У нашій мережі:
- Позитивна вага (+0.3) означає: “якщо вхідний нейрон активний, і цей хочу бути активним”
- Негативна вага (-0.5) означає: “якщо вхідний нейрон активний, і хочу бути менш активним”
- Вага близька до нуля (0.01) означає: “мені байдуже, що робить цей нейрон”
В інспекторі ваги показані як лінії між нейронами. Синій = позитивна вага, червоний = негативна. Товщина лінії = сила зв’язку.
Зміщення (bias, b)
Зміщення — це “поріг чутливості” нейрона. Уявіть, що нейрон — це суддя на змаганнях. Зміщення визначає, наскільки суддя прискіпливий:
- Від’ємне зміщення (b = -2): “Мене важко вразити. Сума сигналів повинна бути дійсно великою, щоб я активувався”
- Додатне зміщення (b = +1): “Я легко вражаюсь. Навіть слабкий сигнал мене активує”
- Нульове зміщення (b = 0): “Я нейтральний”
В нашій мережі 11 зміщень: по одному на кожен з 8 прихованих і 3 вихідних нейрони.
🧪 В інспекторі: Наведіть на будь-який прихований нейрон — поруч побачите
b=0.123. Це зміщення. На епосі 0 всі зміщення = 0 (нейтральні). Прокрутіть до епохи 50 — побачите, як вони змінились.
Частина 3: Прямий прохід — як мережа приймає рішення
Прямий прохід (forward pass) — це процес обчислення від входу до виходу. Як конвеєр на заводі: сировина заходить з одного боку, проходить через кілька станцій обробки, і на виході отримуємо готовий продукт.
Крок 1: Зважена сума (weighted sum)
Кожен прихований нейрон бере всі 25 вхідних значень, множить кожне на відповідну вагу, і додає результати:
z = w₀×x₀ + w₁×x₁ + ... + w₂₄×x₂₄ + bДе:
z— “сира” (raw) сума, це до активації. Може бути будь-яким числом: -5, 0, +12, що завгодноw₀...w₂₄— 25 ваг цього нейронаx₀...x₂₄— 25 значень пікселів (входи)b— зміщення (bias)
Конкретний приклад. Припустимо, подаємо зображення цифри “1” (вертикальна лінія посередині). Пікселі x₂, x₇, x₁₂, x₁₇, x₂₂ = 1 (центральна колонка), решта = 0. Тоді:
z = w₂×1 + w₇×1 + w₁₂×1 + w₁₇×1 + w₂₂×1 + (решта × 0) + b
= w₂ + w₇ + w₁₂ + w₁₇ + w₂₂ + bЗверніть увагу: пікселі зі значенням 0 не вносять вклад у суму. Вага × 0 = 0, незалежно від того, яка вага. Це важливо для розуміння, чому деякі ваги не змінюються при навчанні на певних зразках.
🧪 В інспекторі: Клікніть на прихований нейрон h[0]. В тултіпі побачите повний розрахунок:
z₁[0] = Σ(w·x) + b = 0.348 + (-0.127) = 0.221. Прокрутіть нижче до таблиці “Активні з’єднання (x>0)” — там кожен доданок.
Крок 2: Функція активації — сигмоїда (σ)
Число z може бути будь-яким — від мінус нескінченності до плюс нескінченності. Але нам потрібна активація між 0 і 1. Для цього використовується функція сигмоїда (sigmoid), яку 3Blue1Brown грайливо називає “squishification” (сплющення):
a = σ(z) = 1 / (1 + e^(-z))Що вона робить? Стискає будь-яке число в діапазон (0, 1):
| Вхід z | Вихід σ(z) | Інтерпретація |
|---|---|---|
| -5 | 0.007 | Майже вимкнений |
| -2 | 0.119 | Слабо активний |
| 0 | 0.500 | Нейтральний — рівно посередині |
| +2 | 0.881 | Сильно активний |
| +5 | 0.993 | Майже повністю увімкнений |
Аналогія: сигмоїда — це вимірювач впевненості. Число z — це “сирий бал” нейрона. Сигмоїда перетворює його в “впевненість від 0 до 1”: наскільки впевнений нейрон, що побачив свій патерн.
Чому не просто обрізати? Можна було б сказати: якщо z > 0, то a = 1, інакше a = 0. Але різка границя означає, що маленька зміна z біля нуля може різко змінити вихід, а далеко від нуля — не змінити нічого. Сигмоїда натомість плавна — кожна зміна z дає пропорційну зміну на виході, що критично для навчання (градієнти!).
Крок 3: Від прихованого шару до виходу
Процес повторюється: 3 вихідних нейрони беруть 8 активацій прихованого шару, множать на свої ваги, додають зміщення… але замість сигмоїди використовують softmax.
Крок 4: Softmax — перетворюємо числа в ймовірність
Softmax — це спосіб перетворити 3 довільних числа в 3 ймовірності, що в сумі дають 1 (100%).
Припустимо, 3 вихідних нейрони видали “сирі” значення:
z₂[0] = 2.1 (для цифри 0)
z₂[1] = 0.5 (для цифри 1)
z₂[2] = -0.3 (для цифри 2)Softmax робить 2 кроки:
Крок A — підносимо e до степеня кожного числа:
exp(2.1) = 8.166
exp(0.5) = 1.649
exp(-0.3) = 0.741Навіщо? Дві причини: (1) від’ємні числа стають додатніми (не може бути “від’ємна ймовірність”), (2) різниця між числами підсилюється — лідер відривається ще більше.
Крок B — ділимо кожне на суму всіх:
Сума = 8.166 + 1.649 + 0.741 = 10.556
P(цифра 0) = 8.166 / 10.556 = 77.4%
P(цифра 1) = 1.649 / 10.556 = 15.6%
P(цифра 2) = 0.741 / 10.556 = 7.0%Мережа вважає, що це цифра 0 з впевненістю 77.4%. Сума завжди = 100%.
🧪 В інспекторі: Клікніть на будь-який вихідний нейрон (цифра 0, 1 або 2). Тултіп покаже повний розрахунок softmax з усіма проміжними числами: z₂, exp(z₂), суми, і фінальний відсоток.
Інтерактивний інспектор нейронної мережі
Частина 4: Ініціалізація — з чого все починається
Перед навчанням потрібно задати початкові значення всіх 235 параметрів. Це критичний момент.
Чому не можна почати з нулів?
Якщо всі ваги = 0, то кожен нейрон у прихованому шарі обчислює одне й те саме число. І кожен отримує однаковий градієнт. І оновлюється однаково. Результат: всі 8 нейронів назавжди залишаються ідентичними — мережа фактично має лише 1 прихований нейрон. Це як школа, де всі учні списують один в одного — ніякої різноманітності в знаннях.
He-ініціалізація
Ми використовуємо метод He (Kaiming He, 2015): ваги беруться з нормального розподілу з середнім 0 і стандартним відхиленням √(2/n), де n — кількість входів.
Для нашої мережі:
- W₁ (25→8): σ = √(2/25) ≈ 0.283 — ваги будуть маленькими числами приблизно від -0.57 до +0.57
- W₂ (8→3): σ = √(2/8) = 0.5 — ваги трохи більші, бо менше входів
- Всі 11 зміщень починають з 0
Чому саме √(2/n)? Це магічне число підібране так, щоб сигнал не затухав і не вибухав при проходженні через шари. Занадто маленькі ваги — сигнал зникає до нуля. Занадто великі — числа вибухають до нескінченності. He-ініціалізація тримає баланс.
🧪 В інспекторі: На епосі 0 подивіться на патерни W₁ у правій панелі — 8 кольорових квадратів 5×5. Вони виглядають як випадковий шум. Порівняйте з епохою 100 — тепер кожна картинка показує чіткий патерн (горизонтальні лінії, петлі, вертикальні штрихи).
Частина 5: Функція втрат — як виміряти помилку
Мережа видала прогноз. Але наскільки він хороший? Для цього потрібна функція втрат (loss function) — числова оцінка того, наскільки прогноз далекий від правильної відповіді.
Перехресна ентропія (cross-entropy)
Ми використовуємо cross-entropy loss. Формула проста:
L = -log(P_правильна)Де P_правильна — ймовірність, яку мережа присвоїла правильній цифрі.
Аналогія: уявіть тренера, який не просто рахує правильні/неправильні відповіді, а оцінює впевненість. Якщо ви правильно відповіли “це цифра 0” з впевненістю 95% — відмінно, маленький штраф. Але якщо ви впевнено (90%) сказали “це цифра 1”, а правильна відповідь — 0? Величезний штраф!
| Ситуація | P_правильна | Втрати = -log(P) | Оцінка |
|---|---|---|---|
| Впевнений і правий | 0.95 | 0.051 | Відмінно |
| Сумнівається, але правий | 0.50 | 0.693 | Середньо |
| Впевнений і НЕПРАВИЙ | 0.10 | 2.303 | Погано! |
| Дуже впевнений і НЕПРАВИЙ | 0.01 | 4.605 | Катастрофа! |
Зверніть увагу на нелінійність: різниця між 0.95 і 0.50 — це +0.642 втрати. Але різниця між 0.10 і 0.01 — це +2.302! Впевнено помилитися — набагато гірше, ніж невпевнено помилитися. Це “наскільки здивована мережа, коли дізнається правду.”
🧪 В інспекторі: Втрати показані в лівій панелі як число (наприклад,
loss=1.099) та графік. На епосі 0 втрати — 1.099 — це теоретичний мінімум для випадкового вгадування серед 3 варіантів (-ln(1/3)). На епосі 100 втрати — 0.001 — мережа майже ідеальна.
Частина 6: Градієнтний спуск — як мережа вчиться
Тепер ми знаємо, що мережа помиляється, і ми можемо виміряти наскільки (loss). Питання: як змінити 235 параметрів, щоб помилка зменшилась?
Аналогія: сліпий на горі
Уявіть, що ви стоїте на горі з зав’язаними очима. Ваша мета — спуститися в долину (мінімум втрат). Ви не бачите нічого, але можете відчути нахил землі під ногами. Стратегія проста: зробіть крок у напрямку найбільшого спуску. Повторюйте.
У нашому випадку:
- “Гора” — це функція втрат (loss) як функція 235 параметрів
- “Нахил” — це градієнт: вектор з 235 чисел, кожне з яких каже, як зміна відповідного параметра вплине на loss
- “Крок” — оновлення всіх параметрів одночасно
Градієнт — напрямок найбільшого зростання
Градієнт — це набір часткових похідних, по одній на кожен параметр. Кожна часткова похідна ∂L/∂w каже:
“Якщо ти збільшиш цю вагу на крихітне число ε, втрати зміняться на (∂L/∂w) × ε.”
- ∂L/∂w > 0: збільшення ваги збільшує loss — треба зменшити вагу
- ∂L/∂w < 0: збільшення ваги зменшує loss — треба збільшити вагу
- ∂L/∂w ≈ 0: ця вага майже не впливає на loss — не варто витрачати зусилля
Grant Sanderson пропонує думати про градієнт не як напрямок у просторі, а як рейтинг важливості: “які зміни дадуть найбільший ефект за найменших зусиль.”
Формула оновлення
w_new = w_old − lr × gradientДе:
w_old— поточне значення параметраlr(learning rate, швидкість навчання) — гіперпараметр (число, яке задає людина, не мережа). У нашому випадку lr = 1.2. Визначає розмір крокуgradient— часткова похідна loss по цьому параметру
Мінус у формулі — тому що градієнт вказує напрямок зростання loss, а ми хочемо зменшення.
Learning rate — розмір кроку
Чому lr = 1.2, а не 100 або 0.001?
- Занадто великий lr: кроки надто великі, ви перестрибуєте через дно долини, ритаєтесь туди-сюди, ніколи не зупиняєтесь
- Занадто малий lr: крихітні кроки, навчання займе тисячі епох
- Правильний lr: достатньо великі кроки для швидкого просування, достатньо малі для стабільності
Це один з найважливіших гіперпараметрів. Підбирається експериментально.
🧪 В інспекторі: Клікніть на будь-яке з’єднання (лінію між нейронами) на епосі > 0. В тултіпі внизу побачите повний розрахунок:
Σ(∂L/∂w) = 0.269 avg = Σ/N = 0.269/24 = 0.011 Δw = −lr × avg = −1.2 × 0.011 = −0.013 w_new = w_old + Δw = 0 + (−0.013) = −0.013Наведіть курсор на
lr— побачите пояснення: “Learning rate (швидкість навчання) = 1.2”.
Частина 7: Зворотне поширення помилки — як дізнатися, хто винен
Ми знаємо, що потрібен градієнт — часткова похідна loss по кожній вазі. Але як його обчислити? Від loss до конкретної ваги — довгий ланцюг обчислень. Тут на допомогу приходить backpropagation (зворотне поширення помилки).
Гра в “хто винен?”
Уявіть: мережа побачила цифру 0, але відповіла “2” з впевненістю 60%. Хтось винен. Зворотне поширення працює як слідство:
Крок 1: Помилка на виході. Вихідний нейрон “цифра 2” каже: “Я видав 60%, а правильна відповідь — 0%. Моя помилка = 0.60 - 0 = +0.60”. Нейрон “цифра 0”: “Я видав 15%, а мав видати 100%. Помилка = 0.15 - 1 = -0.85”. Ці різниці (прогноз − мітка) позначаються dz₂.
Крок 2: Хто з прихованих нейронів винен? Помилка повертається по з’єднаннях. Якщо вага між h[3] і “цифра 2” = +0.7, і помилка “цифри 2” = +0.60, то h[3] отримує “звинувачення”: 0.7 × 0.60 = 0.42. Кожен прихований нейрон отримує суму звинувачень від трьох вихідних нейронів.
Крок 3: Прихований нейрон “фільтрує” звинувачення. Прихований нейрон множить отримане звинувачення на похідну сигмоїди σ'(z) = a × (1 - a). Що це означає?
- Якщо
a ≈ 0.5(нейрон невпевнений): σ’ = 0.5 × 0.5 = 0.25 — високе значення. Нейрон чутливий до змін, його легко “переконати” - Якщо
a ≈ 0.99(нейрон дуже впевнений): σ’ = 0.99 × 0.01 = 0.0099 — майже нуль. Нейрон “зациклився” і не хоче змінюватися
Це відоме затухання градієнтів (vanishing gradient): нейрони з дуже високою або дуже низькою активацією практично перестають навчатися.
Крок 4: Оновлення ваг. Тепер ми знаємо gradient для кожної ваги. Для ваги w₂[i][j] (від прихованого j до виходу i):
∂L/∂w₂[i][j] = dz₂[i] × a₁[j]Тобто: помилка виходу × активація прихованого нейрона. Логіка: якщо прихований нейрон був дуже активний (a₁ ≈ 1) і вихід помилився (dz₂ велике), то саме ця вага “винна” — її треба змінити сильно.
Для ваг першого шару w₁[j][k] (від входу k до прихованого j):
∂L/∂w₁[j][k] = dz₁[j] × x[k]Де dz₁[j] — “звинувачення” прихованого нейрона (з кроку 3). Зверніть увагу: якщо x[k] = 0 (піксель вимкнений), то gradient = 0, і ця вага не змінюється. Це логічно: якщо піксель не був активний, вага від нього не могла вплинути на результат, тому немає сенсу її змінювати.
Ланцюгове правило без математики
Весь цей процес — це ланцюгове правило (chain rule) з математичного аналізу, але воно має просту інтуїцію:
Якщо зміна ваги W на крихітне число змінює нейрон A в 3 рази сильніше, а зміна A змінює нейрон B в 0.5 рази, а зміна B змінює loss в 2 рази, то загальний ефект W на loss = 3 × 0.5 × 2 = 3.0.
Множимо ефекти на кожному кроці ланцюга. Це й є backpropagation — ми йдемо від кінця (loss) до початку (ваги) і на кожному кроці множимо “локальний ефект”.
🧪 В інспекторі: Клікніть на з’єднання між h[2] і вихідним нейроном “цифра 0”. Тултіп покаже:
∂L/∂w₂[0][2] = dz₂[0] × a₁[2] dz₂ = a₂ − y (помилка виходу)Нижче — таблиця з 24 зразками: для кожного видно
a₂(прогноз),y(мітка),dz₂(помилка),a₁(активація прихованого нейрона), і результат∂L/∂w.Наведіть на будь-яке число в стовпці
dz₂— побачите повний ланцюг обчислення, включаючи звідки прийшла кожна складова.
Частина 8: Епоха vs зразок — ритм навчання
Тепер найважливіше розрізнення, яке часто плутають:
Всередині однієї епохи
Мережа по черзі дивиться на кожен з 24 навчальних зразків. Ваги і зміщення не змінюються — вони заморожені. Що змінюється — це активації нейронів, тому що кожен зразок має інші вхідні пікселі.
Але при цьому мережа тихо накопичує скарги. Для кожного зразка вона обчислює градієнт: “ця вага повинна бути трохи більша”, “це зміщення — в неправильному напрямку”. Всі ці скарги складаються.
Між епохами
ТІЛЬКИ ТЕПЕР ваги і зміщення змінюються. Мережа бере середню всіх 24 градієнтів і робить один крок оновлення. Потім починається нова епоха — нові заморожені ваги, знову проходимо всі 24 зразки, збираємо нові скарги, оновлюємо.
Епоха 0: випадкові ваги → прогін 24 зразків → зібрати градієнти → ОНОВИТИ ваги
Епоха 1: оновлені ваги → прогін 24 зразків → зібрати градієнти → ОНОВИТИ ваги
Епоха 2: ...
...
Епоха 100: мережа навчена!Аналогія: це як студент, який вивчає весь підручник (= 1 епоха), потім переглядає свої помилки і коригує розуміння. Потім перечитує підручник ще раз — і розуміє більше. Кожен прохід = одна епоха.
🧪 В інспекторі: два слайдери:
- Слайдер епохи: змінює яку версію мозку ви бачите (які ваги/зміщення)
- Слайдер зразка: змінює на що цей мозок дивиться (який вхід подається)
Зафіксуйте епоху 1 і прокрутіть зразки — побачите, як ті самі ваги дають різні активації для різних входів. Потім зафіксуйте зразок і прокрутіть епохи — побачите, як змінюються ваги.
Частина 9: Що відбувається під час навчання — поетапно
Епоха 0: Хаос
Ваги — випадковий шум. Кожен нейрон реагує на довільний набір пікселів. Виходи — 33%/33%/33% — чисте вгадування. Loss — 1.099. Точність — 33%.
Епохи 1–3: Перші кроки
Градієнти найбільші — мережа далеко від оптимуму. Ваги роблять великі стрибки (Δw до 0.05). Деякі нейрони починають “вибирати” спеціалізацію — один реагує сильніше на горизонтальні пікселі, інший на вертикальні.
Епохи 4–10: Швидке навчання
Формуються чіткі патерни. У правій панелі видно, як W₁-картинки з шуму перетворюються на розпізнавані фільтри. Loss різко падає. Точність стрибає з 40% до 80%.
Епохи 11–30: Спеціалізація
Кожен нейрон знайшов свою роль. Один розпізнає верхню петлю (характерна для “0”), інший — вертикальний штрих (характерний для “1”), третій — горизонтальні лінії знизу (характерна для “2”). Градієнти зменшуються — мережа наближається до оптимуму.
Епохи 31–60: Тонке налаштування
Великі зміни позаду. Тепер мережа коригує деталі — підсилює ваги для розрізнення схожих випадків (деякі варіанти “0” схожі на “2”). Зміщення (bias) стають важливими — вони визначаються поріг чутливості кожного нейрона.
Епохи 61–100: Конвергенція
Зміни мінімальні (Δw < 0.00001). Градієнти близькі до нуля. Мережа досягла (локального) мінімуму. Loss — 0.001. Точність — 100%. Всі 235 параметрів оптимізовані.
🧪 В інспекторі: Натисніть ▶ Старт і спостерігайте за всією трансформацією в реальному часі. Слідкуйте за кривою втрат зліва — вона малює типову криву навчання: спочатку плоска (мережа ще не знайшла напрямок), потім різкий спуск (знайшла!), потім плавне вирівнювання (дійшла до дна долини).
Частина 10: Інференс — використання навченої мережі
Після 100 епох навчання ваги заморожені назавжди. Тепер мережа може розпізнавати нові цифри, яких ніколи не бачила.
Інференс (inference) — це просто прямий прохід без навчання:
- Подаємо 25 пікселів нового зображення
- Обчислюємо зважені суми → сигмоїда → зважені суми → softmax
- Дивимось на виходи: [85%, 10%, 5%] — “це цифра 0 з впевненістю 85%”
Жодних градієнтів, жодних оновлень ваг, жодної функції втрат. Просто застосовуємо вивчені “правила” до нових даних. Це як іспит після навчання: студент (мережа) застосовує знання без зворотного зв’язку.
🧪 В інспекторі: Перейдіть у режим “Розпізнавання”. Намалюйте цифру на полотні 5×5 і спостерігайте, як мережа обробляє ваш вхід. Кожен нейрон показує свою активацію, кожне з’єднання — вагу. Клікніть на будь-який нейрон — побачите повний розрахунок прямого проходу.
Словник змінних
| Символ | Назва | Що означає |
|---|---|---|
x[i] | Вхід | Значення i-го пікселя (0 або 1) |
w₁[j][i] | Вага 1 шару | Сила зв’язку від входу i до прихованого нейрона j |
b₁[j] | Зміщення 1 шару | Поріг чутливості j-го прихованого нейрона |
z₁[j] | Зважена сума | w₁·x + b₁ — “сирий” бал перед активацією |
a₁[j] | Активація | σ(z₁) — вихід прихованого нейрона (0..1) |
σ(z) | Сигмоїда | 1/(1+e^(-z)) — стискає число в (0,1) |
σ'(z) | Похідна сигмоїди | a×(1-a) — чутливість нейрона до змін |
w₂[i][j] | Вага 2 шару | Сила зв’язку від прихованого j до виходу i |
b₂[i] | Зміщення 2 шару | Поріг чутливості i-го вихідного нейрона |
z₂[i] | Зважена сума виходу | w₂·a₁ + b₂ |
a₂[i] | Softmax вихід | Ймовірність, що це цифра i (0..1, сума = 1) |
L | Втрати (loss) | -log(P_правильна) — наскільки мережа помилилась |
∂L/∂w | Градієнт | Чутливість loss до зміни ваги w |
dz₂[i] | Помилка виходу | a₂[i] - y[i] — різниця між прогнозом і міткою |
da₁[j] | Зворотний сигнал | Σ(w₂×dz₂) — “звинувачення” від вихідного шару |
dz₁[j] | Градієнт прихов. | da₁ × σ’ — звинувачення з урахуванням чутливості |
lr | Learning rate | Швидкість навчання (гіперпараметр, у нас = 1.2) |
Δw | Зміна ваги | -lr × avg(gradient) — на скільки зсунути вагу |
y[i] | Мітка | Правильна відповідь (1 для правильної цифри, 0 для інших) |
N | Кількість зразків | Скільки навчальних прикладів (у нас = 24) |
Що далі?
Ця крихітна мережа 25→8→3 ілюструє всі ключові принципи, але реальні мережі мають мільярди параметрів і складніші архітектури. Ось що змінюється при масштабуванні:
- ReLU замість сигмоїди:
max(0, z)— швидше обчислюється і не має проблеми затухання градієнтів - Згорткові шари (CNN): замість того щоб кожен нейрон “бачив” усі пікселі, він бачить лише маленьку ділянку — це ефективніше для зображень
- Dropout: під час навчання випадково “вимикаються” частини нейронів — це як примусова різноманітність, яка запобігає перенавчанню
- Batch normalization: нормалізація активацій між шарами для стабільнішого навчання
- Adam замість простого градієнтного спуску: адаптивний lr для кожного параметра окремо
Але в основі всього — ці самі 5 ідей: прямий прохід, функція втрат, зворотне поширення, градієнтний спуск, ітеративне навчання. Все, що ви побачили в інспекторі для 235 параметрів, масштабується на мільярди.
Якщо стаття була корисною, підтримайте мою роботу
Теги:
- нейронна мережа
- зворотне поширення
- градієнтний спуск
- Softmax
- Backpropagation
- Deep learning
- машинне навчання
- візуалізація
- інтерактив